The AI landscape shifted dramatically this week when OpenAI released GPT-5.2—not on their usual carefully orchestrated schedule, but eleven days after declaring an internal “code red” in response to Google’s Gemini 3 advances. For UK business leaders evaluating AI strategy, this isn’t just another model release. It’s a signal that the competitive dynamics driving AI development have fundamentally changed.
The Strategic Context: Why This Release Matters
OpenAI’s rapid response reveals something important about the current AI market: even the perceived leader feels genuinely threatened. The company’s CEO of Applications, Fidji Simo, insisted GPT-5.2 “has been in the works for many months” and that “we don’t turn around these models in just a week.” Yet the timing—less than two weeks after the code red declaration—suggests at minimum an accelerated deployment schedule.
Strategic Reality: When market leaders make defensive moves, the entire competitive landscape shifts. OpenAI’s urgency validates that alternatives like Google Gemini and Anthropic Claude represent genuine competition.
This matters for business strategy because vendor lock-in calculations have changed. A year ago, building on GPT-4 felt like betting on the safe incumbent. Today, the race is genuinely open.
| Competitive Indicator | December 2024 | December 2025 |
|---|---|---|
| Clear market leader | Yes (OpenAI) | Contested |
| Enterprise alternatives | Limited | Multiple mature options |
| Pricing pressure | Minimal | Increasing |
| Model capability gaps | Significant | Narrowing |
| Vendor switching costs | High | Moderate |
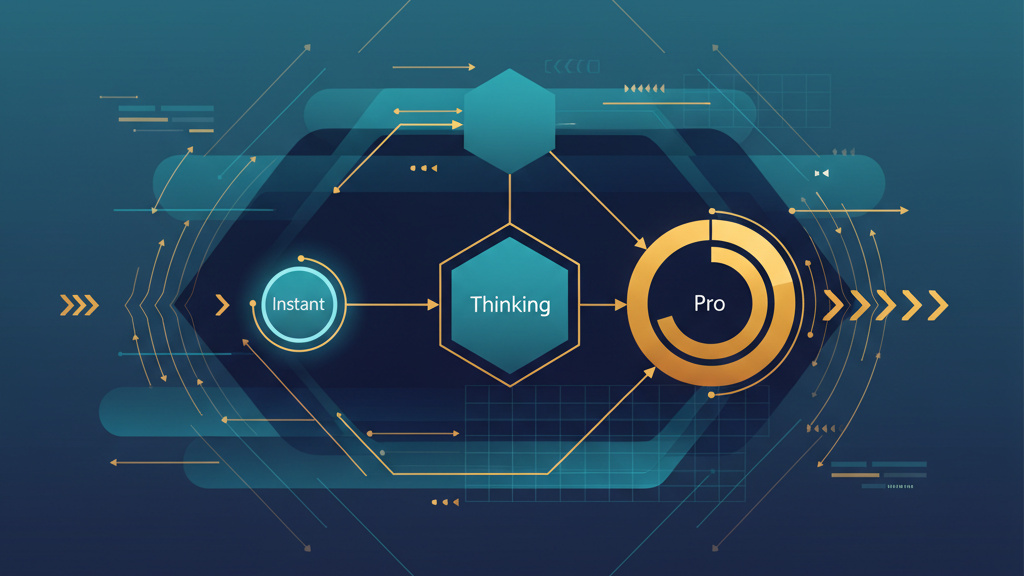
Understanding the Three-Model Architecture
GPT-5.2 arrives not as a single model but as three distinct offerings, each optimised for different use cases. This segmentation represents a strategic shift from OpenAI’s previous “one model fits all” approach.
Instant serves routine queries—information retrieval, writing assistance, and translation. It’s the workhorse model for high-volume, lower-complexity tasks where speed matters more than depth.
Thinking targets complex structured work: coding, document analysis, mathematical reasoning, and planning. OpenAI claims 38% fewer errors than its predecessor in reasoning tasks—a meaningful improvement for workflows where accuracy has real consequences.
Pro delivers maximum accuracy for the most challenging problems. It’s positioned as the premium tier for enterprises requiring the highest reliability.
Implementation Note: This three-tier structure mirrors how businesses actually use AI—routine tasks, analytical work, and critical decisions. Organisations already segmenting their AI usage can map existing workflows directly to the appropriate model tier.
The 400,000-token context window (unchanged from GPT-5.1) means the model can process approximately 300,000 words of context—enough for hundreds of documents simultaneously. The knowledge cutoff of August 2025 represents an eleven-month update from the previous version, addressing a common pain point with outdated information.
The Pricing Reality: Increased Costs, Increased Capability
OpenAI implemented a rare price increase with this release. GPT-5.2 costs $1.75 per million input tokens and $14 per million output tokens—approximately 1.4 times more expensive than GPT-5.1. The Pro tier jumps significantly higher at $21 per million input and $168 per million output.
Critical Context: Price increases during intense competition suggest OpenAI believes their performance improvements justify premium pricing. Whether your organisation agrees depends on measurable value delivered.
For UK businesses running significant AI workloads, these increases compound quickly. An organisation processing 10 million tokens daily faces approximately £15,000 in additional annual costs at current exchange rates. The question becomes whether the capability improvements—particularly the claimed 38% error reduction—generate sufficient value to offset higher costs.
| Model Tier | Input Cost (per million) | Output Cost (per million) | Best Use Case |
|---|---|---|---|
| GPT-5.2 Instant | $1.75 | $14.00 | High-volume routine tasks |
| GPT-5.2 Thinking | $1.75 | $14.00 | Complex analysis, coding |
| GPT-5.2 Pro | $21.00 | $168.00 | Maximum accuracy requirements |
| GPT-5.1 (previous) | $1.25 | $10.00 | Baseline comparison |
Benchmark Claims and Independent Verification
OpenAI’s internal benchmarks paint an impressive picture. On their “GDPval” knowledge work tasks measure, GPT-5.2 achieved 70.9% compared to GPT-5’s 38.8%—nearly doubling performance. The ARC-AGI-2 benchmark jumped from 17.6% to 52.9%.
Third-party validation from the ARC Prize organisation provides perhaps the most striking data point: GPT-5.2 Pro achieved 90.5% on ARC-AGI-1 at $11.64 per task, compared to the previous o3 model’s $4,500 per task. That represents a 390x efficiency improvement in one year.
Success Factor: Self-reported benchmarks warrant healthy scepticism. The ARC Prize validation, however, represents independent testing with real cost implications. A 390x efficiency improvement, even if partially attributable to better task matching, signals genuine capability advancement.
On professional task completion (GDPval), GPT-5.2 achieved 70.9% versus Claude Opus 4.5’s 59.6% and Gemini 3 Pro’s 53.3%. For coding tasks (SWE-Bench Pro), OpenAI scored 55.6%—outpacing Gemini 3 Pro by over 12 percentage points.
Enterprise Positioning and Early Adoption Signals
Alpha testers included Harvey (legal AI), Notion, Box, Shopify, and Zoom. This list reveals OpenAI’s priority markets: legal services, productivity software, cloud storage, e-commerce, and enterprise communications. Notably absent are healthcare, financial services, and government—sectors with stricter regulatory requirements.
SME Advantage: Enterprise alpha programmes typically exclude smaller businesses. However, the lessons from these deployments—documented in case studies and integration guides—become available to all users. Watch for implementation patterns from these early adopters.
The emphasis on “tool use” and “professional knowledge work” suggests OpenAI is positioning GPT-5.2 as infrastructure for AI agents—systems that can take actions, not just generate text. For organisations building or planning agentic workflows, this represents a meaningful capability upgrade.
Anthropic’s Claude currently leads enterprise coding adoption, exceeding OpenAI’s market share in that specific segment. GPT-5.2’s improved coding benchmarks appear designed to address this competitive vulnerability directly.
Implementation Considerations for UK Businesses
The practical question facing UK organisations isn’t whether GPT-5.2 is impressive—it clearly represents advancement. The question is whether and how to incorporate these capabilities into existing AI strategies.
For organisations already using OpenAI products, the upgrade path appears straightforward. The three-tier model structure allows selective adoption: use Instant for existing routine workloads while testing Thinking or Pro for specific high-value applications before broader deployment.
For organisations committed to alternative providers, GPT-5.2’s release doesn’t necessarily change the calculus. Google Gemini and Anthropic Claude continue advancing. The competitive pressure that drove this release benefits all users through continued innovation.
For organisations early in their AI journey, the increasingly competitive landscape actually simplifies decision-making in one respect: no single vendor holds an insurmountable lead. Choosing based on specific capability fit, pricing, and integration requirements makes more sense than betting on a “winner.”
Take Action: Before making vendor decisions, document your actual use case requirements: volume, complexity, accuracy thresholds, and integration needs. Map these against all major providers’ current offerings, not just their marketing claims.
Hidden Challenges Worth Considering
Challenge 1: The Model Selection Problem Three model tiers means more decisions for every implementation. Routing logic—determining which queries go to which model—adds complexity and potential error points. Organisations need clear criteria and monitoring to ensure they’re not overspending on Pro for tasks Instant handles adequately.
Challenge 2: Pricing Volatility This release demonstrates that AI pricing can change rapidly in either direction. Building financial models around current costs requires acknowledging this uncertainty. Budget planning should include scenarios for both price increases (continued capability investment) and decreases (competitive pressure).
Challenge 3: Integration Maintenance API changes accompanying new model releases often break existing integrations. The 128,000 maximum output tokens (up from previous limits) may require adjusting applications designed around smaller response sizes. Factor ongoing maintenance into total cost of ownership.
Challenge 4: Benchmark Translation Impressive benchmark scores don’t automatically translate to your specific use cases. Legal document analysis, customer service automation, and financial modelling each have unique requirements that generic benchmarks may not reflect. Pilot testing with real data remains essential.
Strategic Takeaway
GPT-5.2’s rapid release signals that AI capability advancement will continue accelerating, driven by genuine competition among well-resourced organisations. For UK businesses, this creates both opportunity and complexity.
The core value proposition hasn’t changed: AI tools can meaningfully improve efficiency and capability across numerous business functions. What has changed is the vendor landscape—multiple serious options now exist, competitive pressure is driving innovation and will eventually drive prices, and the “safe bet” of defaulting to any single provider has become less compelling.
Three Success Factors for 2025 AI Strategy
-
Vendor optionality: Design implementations that can migrate between providers. Avoid deep lock-in to any single vendor’s proprietary features.
-
Use case clarity: Document specific requirements before evaluating models. Generic capability claims matter less than performance on your actual workloads.
-
Cost monitoring: Implement granular usage tracking. With three-tier pricing and rising costs, understanding which models serve which functions becomes financially material.
Next Steps Checklist
- Audit current AI usage to identify which model tier fits each use case
- Calculate cost impact of GPT-5.2 pricing on existing workloads
- Test critical workflows against alternative providers (Gemini, Claude) for comparison
- Review integration dependencies that might complicate future vendor switches
- Establish monitoring for accuracy and cost metrics to inform ongoing decisions
This analysis draws on reporting from TechCrunch, Fortune, Simon Willison’s technical analysis, and OpenAI’s official announcements. As with all rapidly evolving technology, specific details may change as additional information becomes available.
Related Resultsense Services
Navigating AI vendor decisions and implementation strategy requires both technical understanding and business context. Our AI Strategy Blueprint helps UK businesses identify practical AI opportunities and create actionable implementation roadmaps. For organisations ready to deploy AI solutions with proper governance, our AI Integration service delivers reliable, human-centred implementations with no vendor lock-in.